Transporter Code Generation
Main concept
Transporters are the active components that move data from an Output Buffer (OB) to the next Input Buffer (IB). This step compiles, for every transporter, the program that performs its scheduled data movements with cycle-level accuracy, using the scheduling and addressing information produced by earlier stages.
In most cases each OB instantiates one transporter, although some memory implementations (such as register files) may require two; code is generated independently for every transporter. Because the transporter is a tightly constrained processor — only 15 usable registers and a minimal instruction set — this is essentially a small compiler with three stages: preprocessing, optimisation, and a backend. They all operate on an intermediate representation (IR).
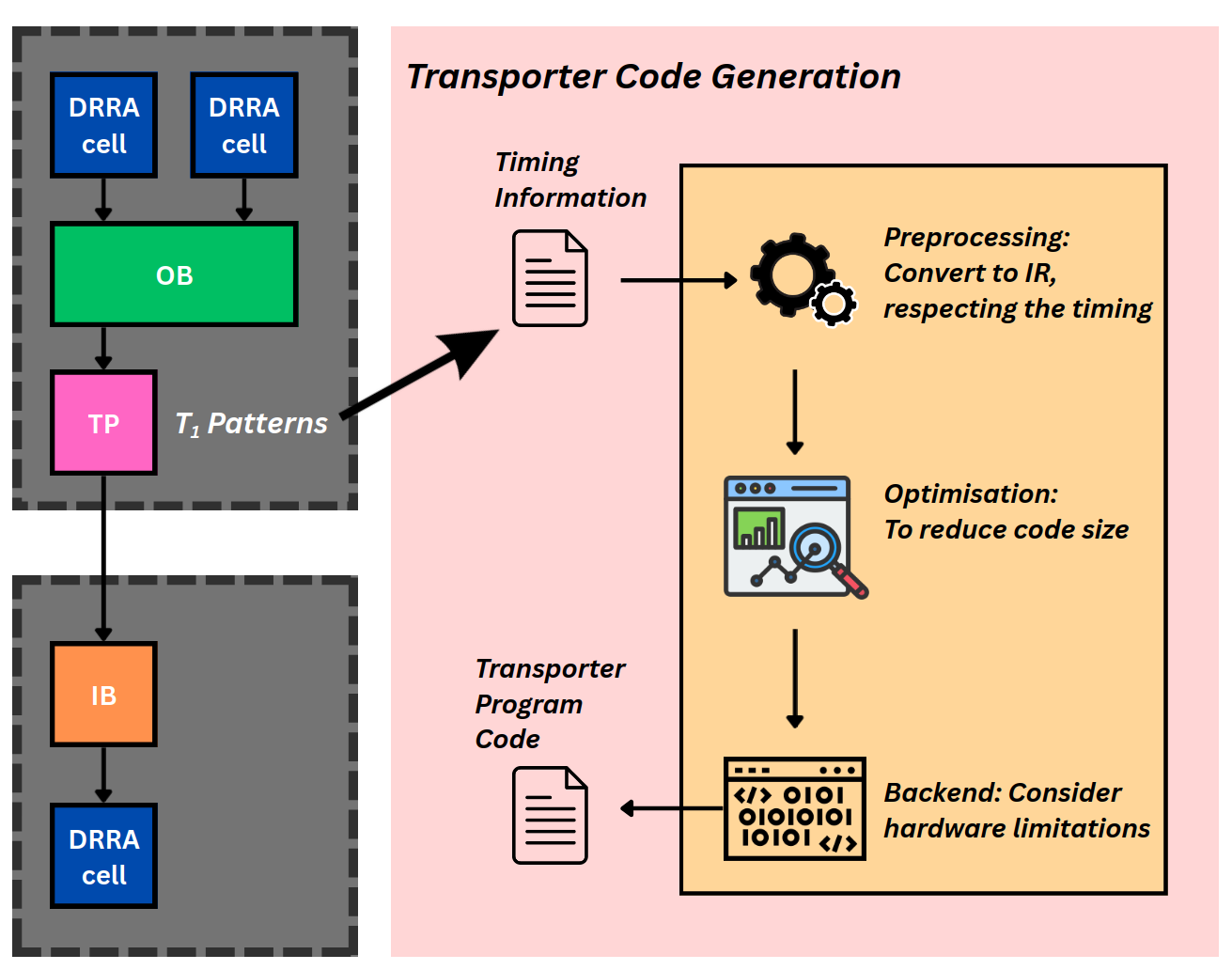 Timing information and the T₁ address patterns are converted to IR (preprocessing), optimised to reduce code size, and lowered to transporter program code (backend).
Timing information and the T₁ address patterns are converted to IR (preprocessing), optimised to reduce code size, and lowered to transporter program code (backend).
Intermediate Representation (IR)
Since the transporter compiler works under strict timing constraints, the IR makes the clock cycle of every instruction explicit. Each IR entry is a (time, instruction) pair, where the instruction is one of the transporter ISA operations:
time instruction
0 NOP
1 LDI R3 16
2 MOV R3 R0 0
Preprocessing
Preprocessing converts the scheduling information — a list of (clock cycle, source
address, target address) triples — into IR. Each transfer becomes one MOV
issued at its scheduled cycle, with the source and target addresses first loaded
into registers by LDI instructions. At this stage an unlimited number of
registers is assumed (no spilling yet), and the LDI instructions that prepare a
MOV are placed at negative time indices, to be scheduled into real cycles later.
input_list -> time instruction
(5, (10, 20)) -4 LDI R4 20
(6, (11, 21)) -3 LDI R3 10
-2 LDI R2 21
-1 LDI R1 11
5 MOV R3 R4 0
6 MOV R1 R2 0
Optimisation techniques
These reduce register usage and final code size:
- Removing redundant registers — if several
LDIinstructions load the same value, keep one and redirect the others to it. - Replacing consecutive
MOVwithMOVC— if a run ofkback-to-backMOVs shares a constant incrementc(so sourceR0 + n·cand destinationR1 + n·cforn = 0…k−1), it collapses to a singleMOVC R0 R1 R2 kwithR2 = c. - Reducing register loads with immediate offsets — the
MOVimmediate field lets the effective addresses besrc = R0 + IMManddst = R1 + IMM, removing someLDIinstructions entirely.
Compiler backend
The backend turns the optimised IR into executable transporter code:
- Removing unused registers — drop
LDIs whose register is never used. - Tightening the timing in the IR — move the
LDIinstructions (initially parked before time zero) into available positive time slots, respecting that anLDImust precede the first use of its register and cannot land on an occupied slot or inside aMOVC. Loads are scheduled most-used-register-first (dependency-driven load scheduling). - Register allocation — map the unlimited "virtual" registers onto the 15 usable physical registers, using the classic pipeline of liveness analysis → interference-graph construction → graph colouring, spilling when colouring fails. When colouring fails, the spill candidate is chosen by the weighted heuristic score below (see the loop afterwards):
where spillability measures how easy it is to insert reloads, liveRangePressure how long the register stays live, interferenceCost the node's degree in the interference graph, and reuseValue how often the register is used. Each term is multiplied by an adjustable weight.
loop {
let lives = liveness(&ir);
let graph = interference_graph(&ir, &lives);
let colours = graph_colouring(&ir, &graph);
if colours.success { break; }
transforming_ir(&mut ir, colours.spilled_register);
}
- Filling
NOPinstructions — insertNOPs into every empty time slot so the real instructions execute on exactly their scheduled cycles, and append a finalNOP 0so the transporter stalls after it finishes. - Final check and code generation — validate value bounds, report the transporter's start time, end time and execution latency back to Sylva (start times may be negative here and are resolved during Control Synthesis), and emit the final binary following the ISA.
Why it matters
Program size directly determines the transporter's instruction-memory area. For
regular, affine patterns (e.g. the Sobel example) the MOV→MOVC optimisation can
roughly halve the instruction count; for irregular patterns (e.g. most LeNet-5
edges) it rarely applies, and code size is dominated by per-transfer LDI
overhead.